FeatUp: A Model-Agnostic Framework
for Features at Any Resolution
ICLR 2024
Stephanie Fu*, Mark Hamilton*, Laura Brandt, Axel Feldman, Zhoutong Zhang, William T. Freeman
*Equal Contribution
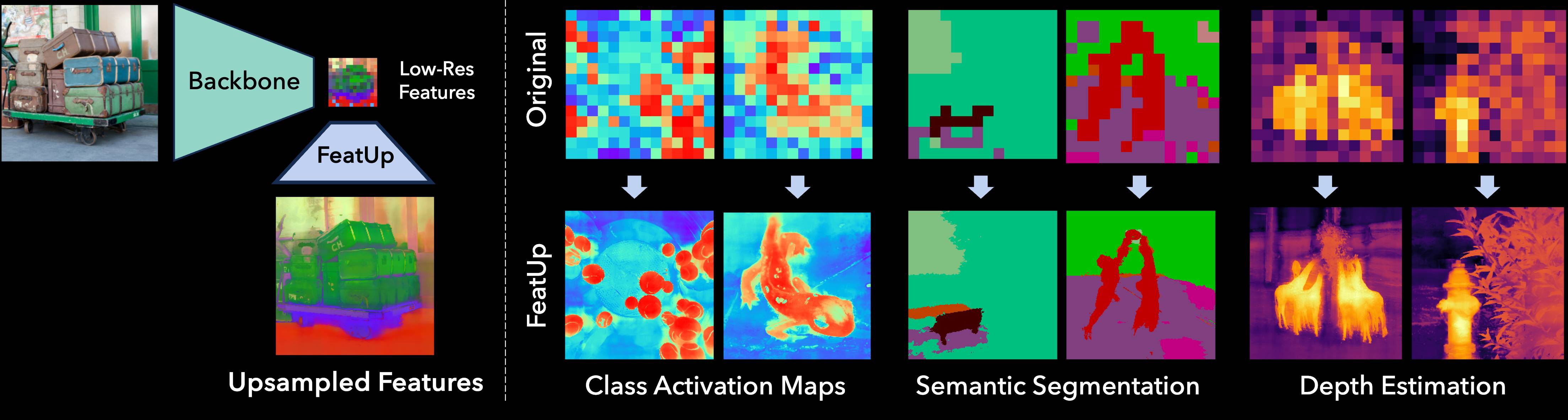
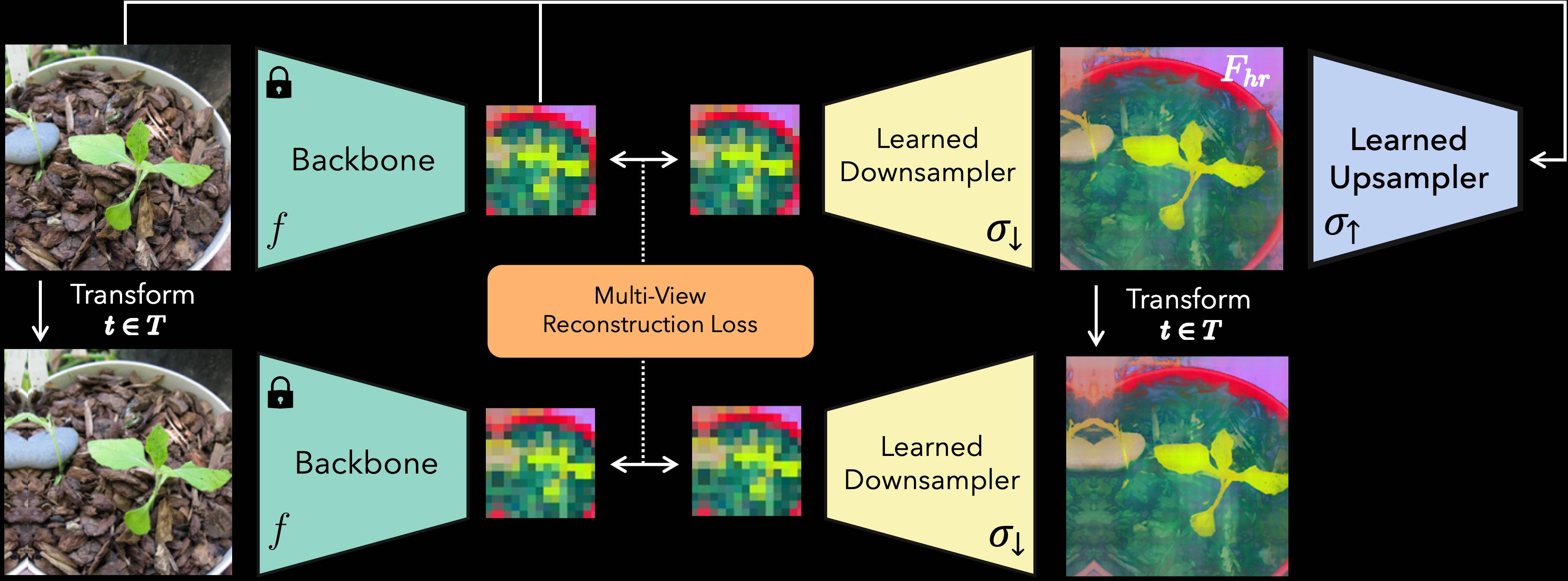
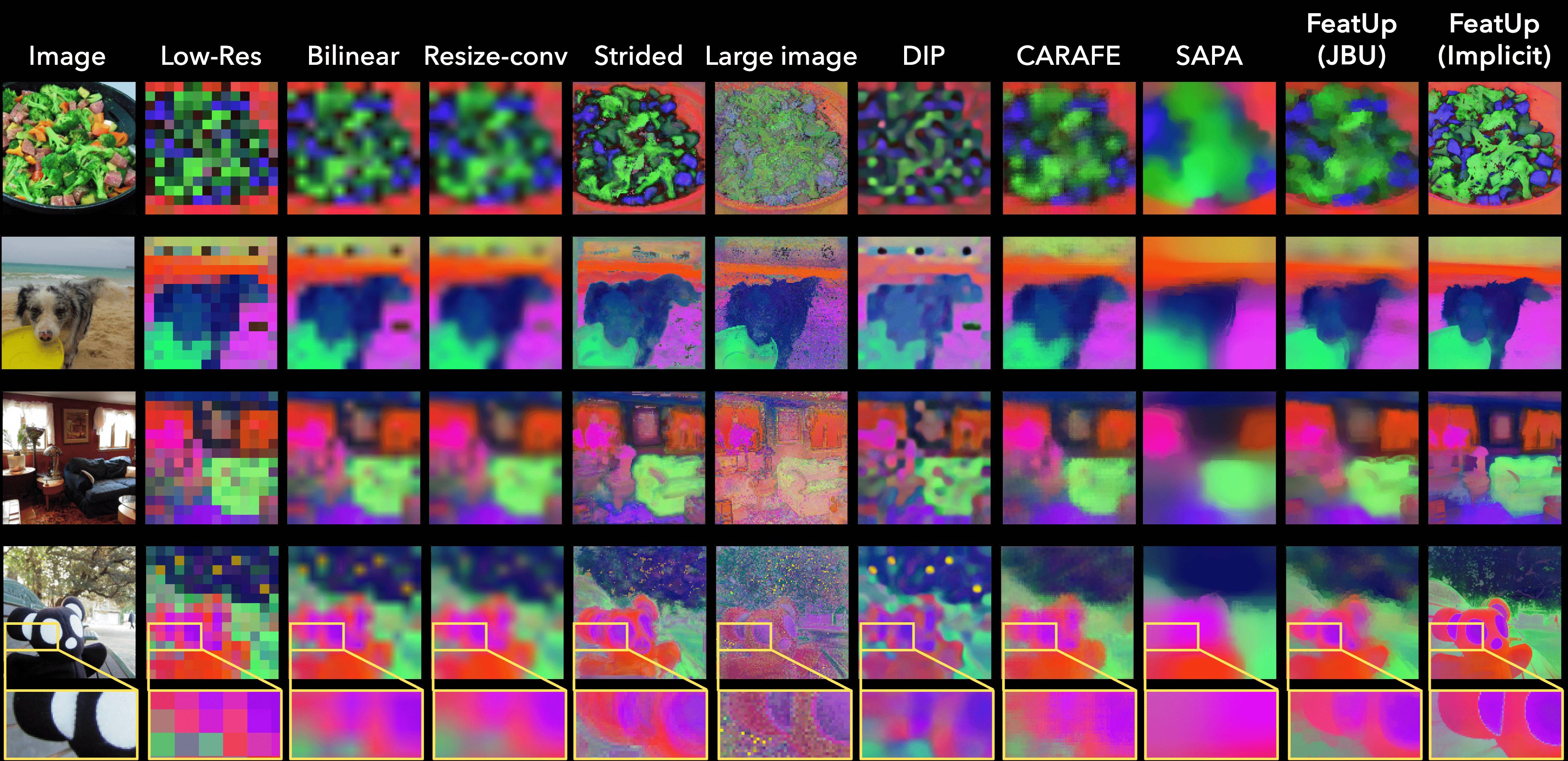
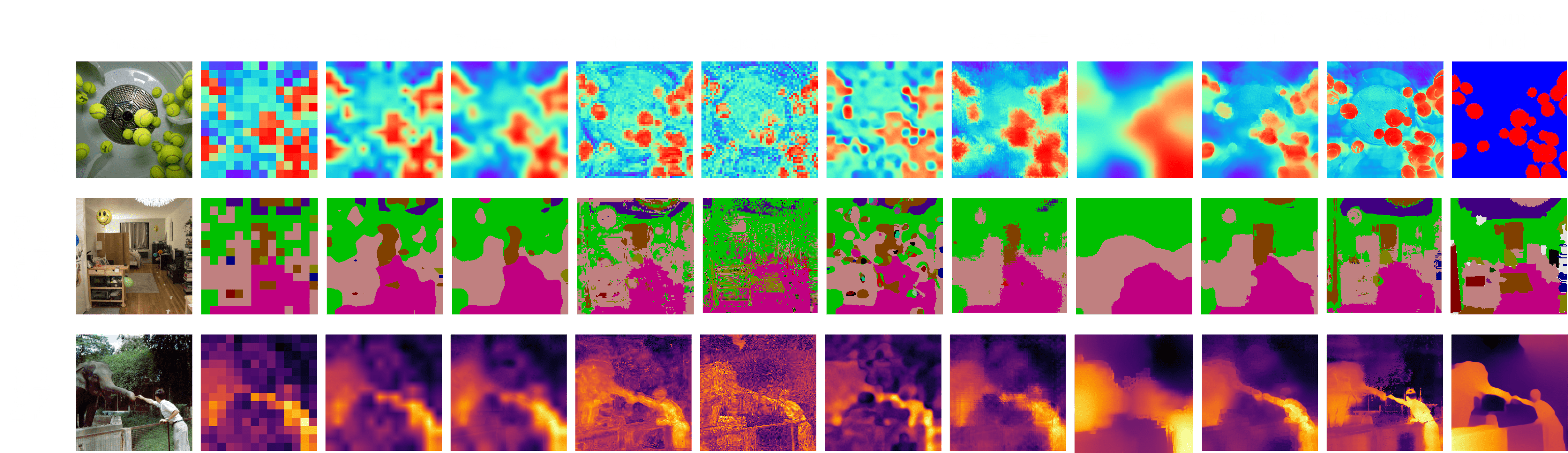
TL;DR: FeatUp improves the spatial resolution of any model's features by 16-32x without changing their semantics.
Examples
Video
DINO
DINO+FeatUp
Video
DINO
DINO+FeatUp
Video
DINO
DINO+FeatUp
Video
DINO
DINO+FeatUp
Video
DINO
DINO+FeatUp
Video
DINO
DINO+FeatUp
Any Backbone:
Video
ViT
DINO
DINOv2
CLIP
RN50
Improve Downstream Tasks without Retraining :
Video
Semseg Probe
Depth Probe
CAM (Horse)
CAM (Bars)
Upsamples Every Feature Dimension:
Video
DINO PCA 1,2,3
DINO PCA 4,5,6
DINO PCA 7,8,9