Humans have been shown to use a “straightened” encoding to represent the natural visual world as it evolves in time (Henaff et al. 2019). In the context of ´discrete video sequences, “straightened” means that changes between frames follow a more linear path in representation space at progressively deeper levels of processing. While deep convolutional networks are often proposed as models of human visual processing, many do not straighten natural videos. In this paper, we explore the relationship between network architecture, differing types of robustness, biologically-inspired filtering mechanisms, and representational straightness in response to time-varying input; we identify strengths and limitations of straightness as a useful way of evaluating neural network representations. We find that (1) adversarial training leads to straighter representations in both CNN and transformer-based architectures but (2) this effect is task-dependent, not generalizing to tasks such as segmentation and frame-prediction, where straight representations are not favorable for predictions; and nor to other types of robustness. In addition, (3) straighter representations impart temporal stability to class predictions, even for out-of-distribution data. Finally, (4) biologically-inspired elements increase straightness in the early stages of a network, but do not guarantee increased straightness in downstream layers of CNNs. We show that straightness is an easily computed measure of representational robustness and stability, as well as a hallmark of human representations with benefits for computer vision models.
The Straightness of a Representation
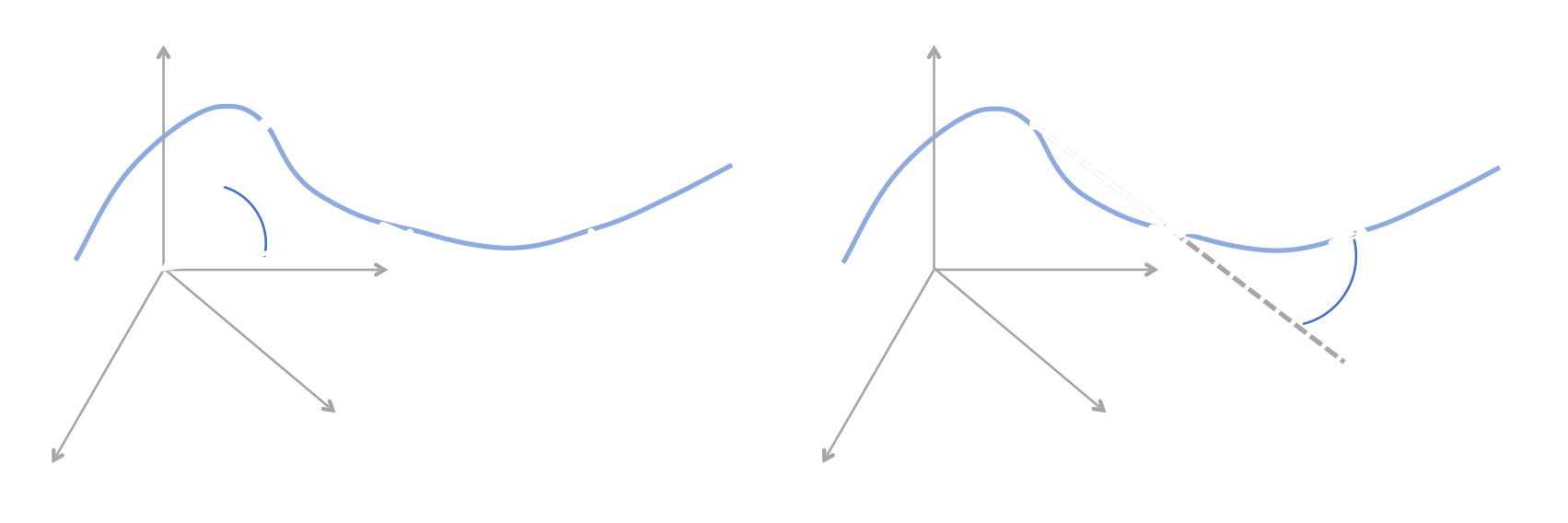
The curvature of a representation refers to the smoothness or linearity of the trajectory of visual input over time in some representation space. Humans tend to use a straightened encoding to represent the natural visual world as it evolves in time (Henaff et.al.). Straighter representations can be useful for visual tasks that require extrapolation, such as predicting the future visual state of the world. We investigate how and where representational straigntness arises in algorithms.
Measuring Straightness
To compute the curvature of a video sequence, we look at the velocity vectors of the representation over time. This can be done at any stage of the processing pipeline, from raw input pixels to activations of a network's hidden layer. To compute the curvature at each time step we find the angle between successive velocity vectors. We define the global curvature as the average angle over all time steps. This provides a simple measurement of how straight the sequence of video frame representations is.
Robust Models have Straighter Representations
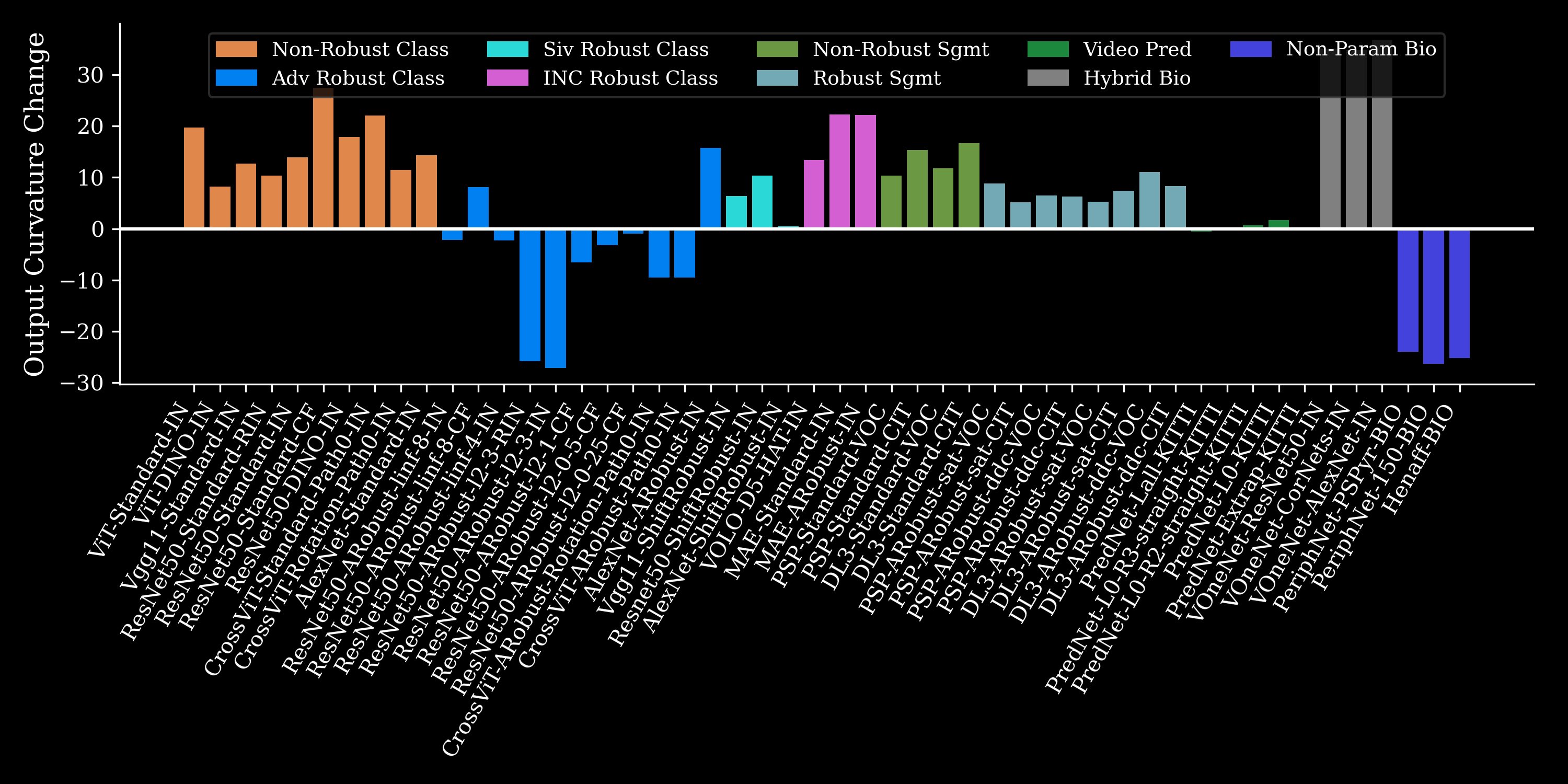
We explored the relationship between model type, adversarial attack type and strength, and output curvature in image recognition models. We find that adversarially trained models tend to have lower curvature compared to non-adversarially trained models. Furthermore, we show that higher robustness to adversarial perturbations leads to straighter representations. This is particularly useful in fields such as robotic vision where objects are observed from different angles over time. Overall, we found that lower curvature results in a more stable predictions over time, which is beneficial in various applications.
Paper
Bibtex
@inproceedings{ harringtonexploring, title={Exploring perceptual straightness in learned visual representations}, author={ Harrington, Anne and DuTell, Vasha and Tewari, Ayush and Hamilton, Mark and Stent, Simon and Rosenholtz, Ruth and Freeman, William T}, booktitle={The Eleventh International Conference on Learning Representations} }
Contact
For feedback, questions, or press inquiries please contact annekh@mit.edu and vasha@mit.edu